
Alle programmeringssprog kan bruges til at analysere data. Nogen er bedre til det end andre. Anaconda er et udviklingsmiljø med udgangspunkt i Python, der har samlet adgangen til en række af disse værktøjer.
Et af disse værktøjer er Jupyter Notebook: Et udviklings- og præsentationsværktøj, der giver dig mulighed for at kombinere dit Python program (og andre programmer) med programmets uddata og smukt formatterede markdown kommentarer. Her er fx en lille stump af vores Jupyther Notebook med beregning af epidemiske spredninger:
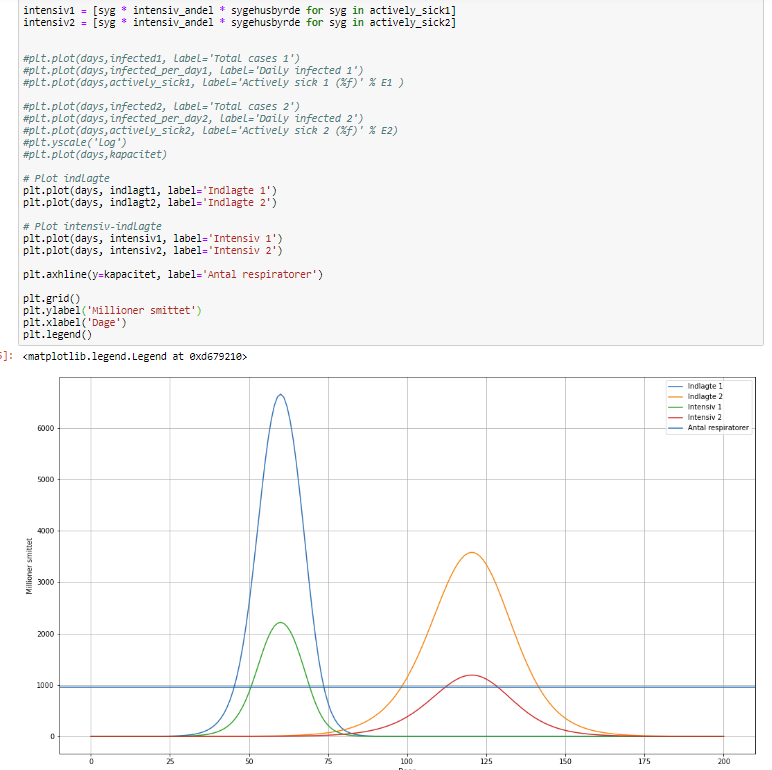
En Jupyther notebook kan oven i købet relativt let publiceres ved at bruge nbviewer. Her er fx et af vore (Roalds) epidemiberegningsprogrammer: SIR-model, men man kan opnå endnu tættere samarbejde ved at installere en Jupyther Hub, som er en cloud installation af Jupyther Notebook, så flere programmører og dataforskere kan arbejde sammen på den samme Notebook.
En anden mulighed for at præsentere data, så læseren selv dynamisk kan ændre, hvad der vises (ud over de dyre kommercielle systemer fra fx SAS), er fx Shiny for R.
Meget af det arbejde, der indgår i Anaconda og Jupyther udføres af uafhængige udviklere verden over i opensource samarbejde. Det betyder, at der er utrolige mængder af tilgængelige udvidelser og programkode. Se fx her hvis du vil have en introduktion til Bayesian statistics (de metoder, der bl.a. benyttes til at afgøre om en mail er spam, men mere generelt til at skabe struktur på store tekstmængder, som ikke umiddelbart ser ud til at indgå i en strukturel sammenhæng).